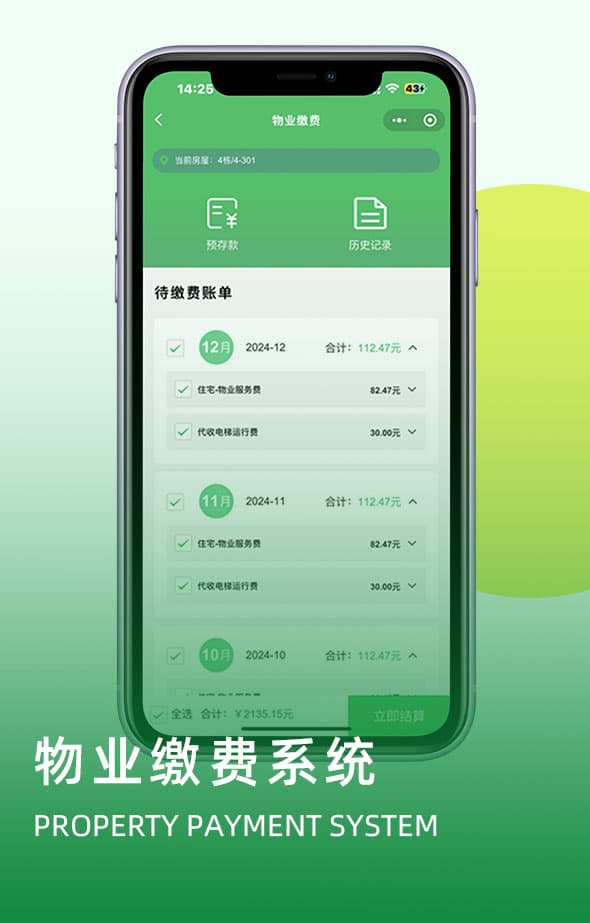
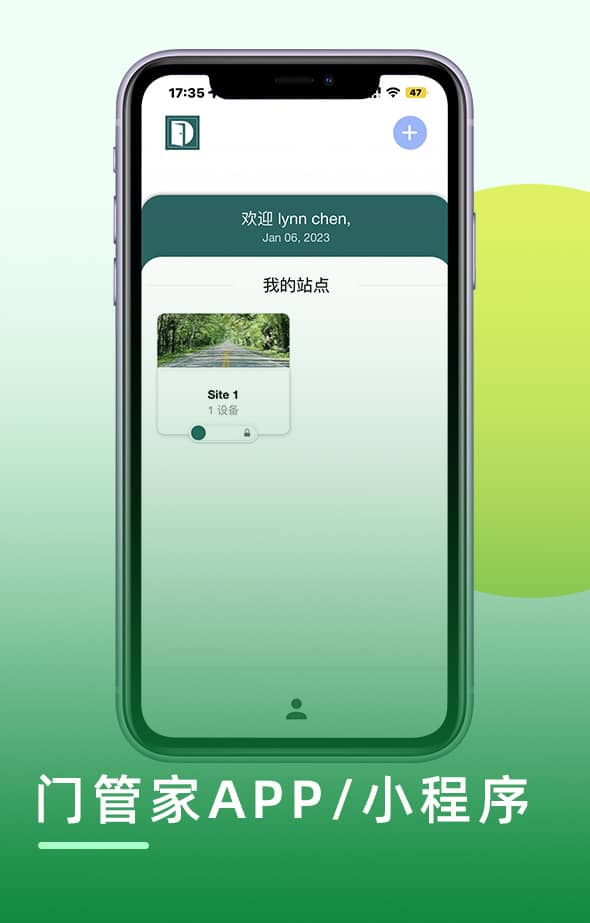
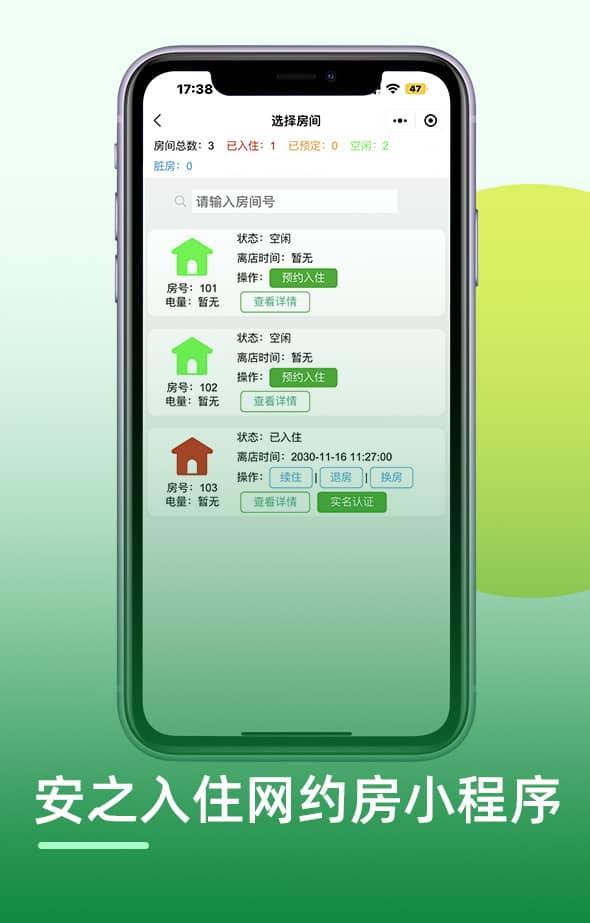
西墨是一家专注于物业行业数字底座建设的国家高新技术企业,立志于为每个物业提供更好的智能化产品和服务。已为全球数万家地产物业和企业客户提供服务,2020年被评为深圳市龙岗区中小企业创新50强。公司在智慧社区智慧园区平台、智能硬件、互联网音视频通信、人工智能方面有深厚的技术积累;拥有业界领先的基于移动互联网的智慧社区、智慧园区、公租房出租屋系列产品及解决方案,主打人脸识别云对讲、手机蓝牙二维码云门禁、停车场、充电桩、梯控、访客、消防、智能锁、节能灯节能模块等物联网产品及云平台;为星河、鸿荣源、万科、建设银行、农业银行、金科、华润、长城、宏阳、佳兆业、保利物业、中移物联网、珠江地产、首开等国内多家著名品牌房地产、互联网、安防企业提供产品及服务;产品远销美国、巴西、马来西亚、新加坡、智利、英国等海外客户。兼爱利他、以墨爱人,公司本着贴近客户、精益求精、优质体验的经营理念,开放共赢制造精品,以精品回报客户,服务物业管理,建设美好生活! !